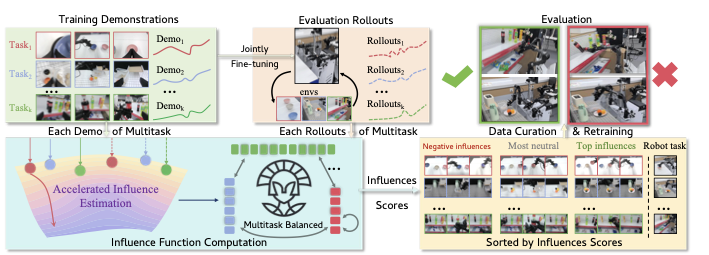
In robot imitation learning, influence functions provide a principled approach to quantify each demonstration's effect on robot task outcomes, yet scaling them to billion-parameter Vision-Language-Action (VLA) models is limited by computational and multitask bottlenecks. To this end, we propose ATHENA, an influence function framework tailored for multitask VLA data curation at billion-parameter scale. Concretely, it leverages the Kronecker structure of linear-layer gradients to reduce projection cost, and approximates dense Hessian inversion with a rank-$r$ Random Truncated Approximation, achieving about a 313.4x speedup in influence computation. Furthermore, ATHENA formulates global and local interactive influence to balance data curation across 50 jointly trained tasks. Extensive evaluations on RoboTwin 2.0 and real-robot deployment, covering 9.34 and 6.90 hours of demonstrations, respectively, show that ATHENA matches or exceeds full-data joint fine-tuning using only 50% of demonstrations in simulation and 66.7% of data across six real-robot tasks. Overall, ATHENA demonstrates its effectiveness for data curation in billion-parameter multitask VLA fine-tuning.
We evaluate ATHENA on six real-robot ALOHA tasks spanning three different difficulty levels. The videos below compare the performance of ATHENA, Oracle, and the Full-Data baseline. The percentages in parentheses indicate the proportion of demonstration data retained for fine-tuning. Notably, both ATHENA and Oracle use exactly 66.7% of the original data.