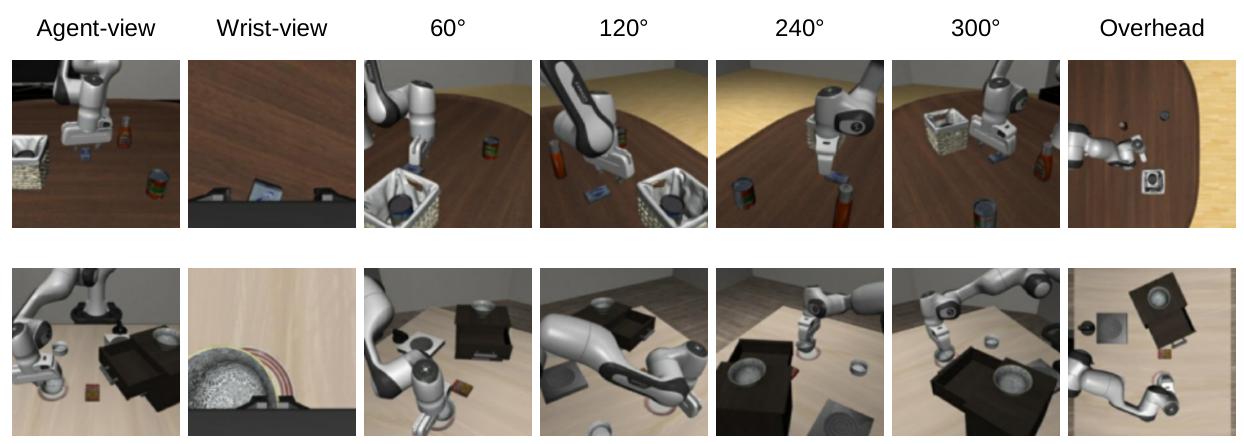
UniviewVLA pipeline.
UniviewVLA models language instructions, multiview observations, and actions with discrete tokens that can be autoregressively predicted by a unified Transformer model, using two training stages and dynamic inference.
(1) Multiview world model post-training. UniviewVLA takes language instructions, standard agent-view, and wrist-view inputs, and autoregressively generates future multiview images that incorporate multiview and world evolution information.
(2) Action fine-tuning. UniviewVLA first predicts compact motion-informative tokens to avoid the high latency of full auxiliary-view tokens, and then predicts FAST action tokens.
(3) Dynamic inference. During inference, transparent cameras denote generated auxiliary views, and the green camera denotes the selected auxiliary view. UniviewVLA periodically selects the best auxiliary view for action prediction across different inference stages instead of using a fixed viewpoint.